UChicago Scientists Receive Grant to Expand Global Data Management Platform, Globus
Whether one is a high energy physicist or geneticist, research across many different disciplines rely increasingly on more distributed cyberinfrastructure — where data is stored and produced in several locations, analyzed in others, and shared or published in yet another location. This has supported new discoveries at an exciting rate, but also creates a new problem: how to locate, organize, and manage data that is now scattered.
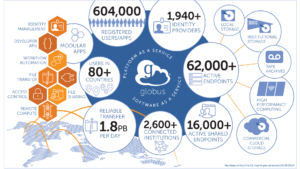 To solve this problem, researchers from the Department of Computer Science at the University of Chicago created a non-profit cloud platform, called Globus, that allows researchers to manage and access their data in the cloud. Globus currently has over 2,600 connected institutions and 604,000 users across over 80 countries and has been used to transfer several exabytes of data.
To solve this problem, researchers from the Department of Computer Science at the University of Chicago created a non-profit cloud platform, called Globus, that allows researchers to manage and access their data in the cloud. Globus currently has over 2,600 connected institutions and 604,000 users across over 80 countries and has been used to transfer several exabytes of data.
However, while Globus has made it easier for researchers to manage their data across these different locations, the cloud service still requires that people have prior knowledge of where the data resides. Research Associate Professor Kyle Chard, Arthur Holly Compton Distinguished Service Professor of Computer Science Ian Foster, and researcher Ben Blaiszik were awarded an NSF Grant that plans to address this issue.
The team will be enhancing Globus to provide new search capabilities in the existing Globus platform. This new capability will allow researchers to search for data across multiple locations, and also develop high level capabilities to index these distributed locations to access metadata and content. This eliminates the need for prior knowledge about specific data files from the researcher. Globus will be able to index not only the file system metadata — which is the file names and paths— but also be able to index the contents of the file itself.
“Increasingly, we see people not just finding data and using ordinary search but relying on machine learning models that extract features from data automatically,” Foster states. “We want to be able to allow people to construct and apply machine learning classifiers to data that may be distributed over many file systems, and find data that is similar to the data they have at hand, but perhaps that they didn’t realize was similar.”
Although indexing and searching is not new, the challenge the team faces is having to deal with extremely specialized, scientific data. In addition to the sheer scale of this project (Globus must keep up with the rate of change of billions of files stored in supercomputers), the system must also be created with a common mechanism that will work across different storage systems, from typical file systems to archival tape storage, specialized parallel file systems, and the many cloud object stores available.
Chard and Foster also have to develop an authorization model to go with Globus’ distributed indexing algorithm. Globus has an outstanding reputation for data security, and much of the world’s most important scientific data is managed through the platform. For instance, biomedical and protected data are both managed with Globus. While developing the authentication and authorization methods in Globus took decades of research and development to get to this point, this project will move towards that same level of assurance and ability to handle protected data. For now, Chard and Foster plan to implement a rich authorization model that is layered on top of Globus Auth and existing technologies from Amazon Web Services and Elastic Search.
“It’s very important to manage who’s allowed to access metadata, because the metadata will often have important scientific information in it,” Chard states. “That could be an individual scientist, or it could be a large collaboration. We have metadata collected from these hundreds of petabytes of data, and Globus will implement careful control over who’s allowed to access each piece of metadata, and that can be changed over time as collaborations develop.”
Millions of scientists around the world are generating vast amounts of data every day, but much of this valuable information is never reused by other researchers. Chard and Foster hope that the enhancements to Globus will make it easier to find and access data that are created by all sorts of different fields. Currently, it’s already becoming easier over time to find and access data, but no one knows the full extent of the data that is available, and therefore don’t access it or do research with it. By making it easy to index and catalog data, Chard and Foster hope that it will become much simpler to find and use that information, which in turn can accelerate the pace of scientific progress.
Foster remarks, “One question that NSF is asking, and we don’t really know how to answer, is how do you evaluate whether you’ve succeeded in increasing the rate of scientific discovery? I don’t know how to do that yet, except by seeing who might cite our work when they announce a result. However, I think it’s clear that people can discover information more easily with a tool like Globus and these new search capabilities. They will be able to answer questions that they couldn’t have answered before.”